Dagster’s asset-first approach offers a refreshing perspective on data orchestration. Today, I want to share a hands-on journey building a complete Spotify Data Pipeline that puts these ideas into practice. It’s remarkable how shifting to think in terms of assets can transform the way you approach pipeline development.
I’ve always found that the best way to understand a new tool is to build something meaningful with it. We’ll extract artist data from Spotify, transform it through a Medallion Architecture (bronze → silver → gold), and create consolidated artist insights ready for analysis. This project represents a practical implementation of the concepts we’ve discussed - bringing theory into the realm of working code.
Data Engineering with a soundtrack - let’s get started.
Project Overview

Our pipeline will collect and process artist data from Spotify through three increasingly refined layers:
bronze: raw.jsondata extracted directly from Spotify’s API using Python.silver: transformed and structured.parquetdata using DuckDB.gold: consolidated insights combining metrics into.parquetformat using DuckDB.
This structure provides clarity to our data transformation process. Raw data arrives first, then gets transformed into something more structured, and finally becomes refined into business-ready insights. Each layer has a distinct purpose - bronze captures the raw API responses, silver provides cleaned and normalized information in an analytics-friendly format, and gold delivers the final transformed insights ready for analysis. This approach lets us focus on demonstrating Dagster’s capabilities rather than building a complete Data Lake with historical versioning.
Setting the Stage
Now that we understand the components of our pipeline, let’s set up the development environment. Since Dagster is fundamentally a Python framework, we only need a Python environment to handle the entire project. This is one of Dagster’s strengths - it doesn’t require separate infrastructure or services to get started.
For dependency management, I’m using uv, a blazing-fast Python package installer and resolver. If you’re not familiar with it, it’s worth checking out - it makes virtual environment management much more pleasant than traditional tools. Our project requires just a few dependencies, which we’ll add to our pyproject.toml:
dependencies = [
"dagster>=1.10.6",
"dagster-webserver>=1.10.6",
"dagster-duckdb>=0.26.6",
"requests>=2.32.3",
]Dagster needs some specific configuration to work smoothly with modern Python tooling. Let’s add these properties to our pyproject.toml:
[tool.dagster]
module_name = "project.definitions"
code_location_name = "project"
[tool.setuptools.packages.find]
include = ["project"]
I called this project project - yes, I know, I’ve truly been blessed with the gift of creativity.
For larger projects, you might want a more structured approach with separate folders for each component type, but for our demonstration, a flat structure works well. Here’s our project layout:
.
├── data
│ ├── bronze
│ ├── silver
│ └── gold
├── project
│ ├── assets.py
│ ├── definitions.py
│ ├── partitions.py
│ └── resources.py
└── pyproject.toml
The structure aligns perfectly with our Medallion Architecture, with dedicated directories for each layer’s output. Within the Python package, we’ve organized our code to match Dagster’s component model - separating assets, resources and partitions while keeping them all accessible.
Finally, we need a .env file in the root directory to store our Spotify API credentials. This simple approach works for this tutorial, but in production, you might want a more robust solution like a secrets management service.
SPOTIFY_API_CLIENT_ID=...
SPOTIFY_API_CLIENT_SECRET=...And that’s it. We are all set - now we can start the show.
Setting Up the Resources
First, we need to connect to Spotify’s API. Before diving into the code, let’s address the prerequisites: we’ll need a Spotify developer account and registered application to get our client ID and secret. We can head over to the Spotify Developer Dashboard, create an account if we don’t have one already, and register a new application. Once that’s done, we’ll have the credentials needed for our pipeline.
# ./resources.py
import base64
import time
from typing import Any, Optional
import requests
from dagster import ConfigurableResource
from pydantic import BaseModel
class SpotifyAPIError(Exception):
"""Exception raised for Spotify API errors."""
pass
class SpotifyToken(BaseModel):
"""Spotify authentication token with expiration tracking."""
access_token: str
expires_at: float
def is_valid(self) -> bool:
"""Check if token is still valid."""
return time.time() < self.expires_at
class SpotifyAPI(ConfigurableResource):
"""Resource for interacting with the Spotify Web API."""
client_id: str
client_secret: str
# API endpoints and constants
BASE_URL: str = "https://api.spotify.com/v1"
AUTH_URL: str = "https://accounts.spotify.com/api/token"
TOKEN_EXPIRY_BUFFER: int = 300 # 5 minutes safety buffer
def __init__(self, **kwargs) -> None:
super().__init__(**kwargs)
self._token: Optional[SpotifyToken] = None
def _get_auth_token(self) -> str:
"""Get or refresh Spotify authentication token using client credentials flow."""
# Return cached token if still valid
if self._token and self._token.is_valid():
return self._token.access_token
# Prepare authentication credentials
credentials: str = base64.b64encode(
f"{self.client_id}:{self.client_secret}".encode("utf-8")
).decode("utf-8")
response: requests.Response = requests.post(
url=self.AUTH_URL,
headers={
"Authorization": f"Basic {credentials}",
"Content-Type": "application/x-www-form-urlencoded",
},
data={"grant_type": "client_credentials"},
)
if response.status_code != 200:
raise SpotifyAPIError(f"Authentication failed: {response.text}")
# Create token with calculated expiry time
result: dict[str, Any] = response.json()
self._token = SpotifyToken(
access_token=result["access_token"],
expires_at=time.time() + result["expires_in"] - self.TOKEN_EXPIRY_BUFFER,
)
return self._token.access_token
def _make_api_request(
self, endpoint: str, params: Optional[dict[str, Any]] = None
) -> dict[str, Any]:
"""Make authenticated request to Spotify API with automatic token refresh."""
url: str = f"{self.BASE_URL}/{endpoint}"
# Get token and make requests
response: requests.Response = requests.get(
url=url,
headers={"Authorization": f"Bearer {self._get_auth_token()}"},
params=params,
)
# If unauthorized, token might be expired - refresh and retry once
if response.status_code == 401:
self._token = None
response = requests.get(
url=url,
headers={"Authorization": f"Bearer {self._get_auth_token()}"},
params=params,
)
if response.status_code != 200:
raise SpotifyAPIError(f"API request failed: {response.status_code} - {response.text}")
return response.json()
def _get_artist_id(self, artist: str) -> str:
"""Search for an artist by name and return their Spotify ID."""
params: dict[str, Any] = {
"q": f"artist:{artist}",
"type": "artist",
"limit": 1,
}
response: dict[str, Any] = self._make_api_request(endpoint="search", params=params)
items: list[dict[str, Any]] = response.get("artists", {}).get("items", [])
if not items:
raise SpotifyAPIError(f"No artists found for '{artist}'")
return items[0]["id"]
def get_artist(self, artist: str) -> dict[str, Any]:
"""Get all albums for an artist"""
id: str = self._get_artist_id(artist=artist)
results: dict[str, Any] = self._make_api_request(endpoint=f"artists/{id}")
return results
def get_artist_albums(self, artist: str) -> list[dict[str, Any]]:
"""Get all albums for an artist by name."""
id: str = self._get_artist_id(artist=artist)
results: dict[str, Any] = self._make_api_request(
endpoint=f"artists/{id}/albums", params={"limit": 50, "market": "BR"}
)
if "items" not in results:
raise SpotifyAPIError("Unexpected API response: 'items' field missing")
return results["items"]
def get_artist_top_tracks(self, artist: str) -> list[dict[str, Any]]:
"""Get top tracks for an artist by name."""
id: str = self._get_artist_id(artist=artist)
results: dict[str, Any] = self._make_api_request(
endpoint=f"artists/{id}/top-tracks", params={"market": "BR"}
)
if "tracks" not in results:
raise SpotifyAPIError("Unexpected API response: 'tracks' field missing")
return results["tracks"]
This SpotifyAPI resource does more than just wrap the Spotify API. It thoughtfully handles authentication with automatic token refresh (saving us from those mid-run failures), provides dedicated exceptions for error handling, implements caching to reduce API calls, and offers clean interfaces for retrieving the exact data we need.
The design separates how to access Spotify from our pipeline logic, which is exactly what resources in Dagster are meant to do. This separation makes our code more testable and maintainable. When testing, we can substitute this resource with a mock version without changing any pipeline code, giving us confidence that our tests reflect real-world scenarios.
The difference between a fragile pipeline and a robust one often comes down to how carefully resources like these are designed. Taking the time to build a thoughtful abstraction pays dividends when you’re not frantically debugging authentication failures at inconvenient times.
Defining Our Data Partitions
Now we’ll define the scope of data we’re processing by creating partitions for different artists:
# ./partitions.py
from dagster import StaticPartitionsDefinition
ARTISTS = StaticPartitionsDefinition(
partition_keys=[
"Charlie Brown Jr.",
"Eminem",
"Imagine Dragons",
"Johnny Cash",
"Linkin Park",
"Red Hot Chili Peppers",
"Twenty One Pilots",
]
)
This approach allows us to process data for each artist independently. We can run operations in parallel, selectively refresh data for specific artists, and add more artists without modifying our pipeline code. The partitions create a natural organization that makes our pipeline both scalable and maintainable.
For this implementation, I’ve populated the partitions with my favorite artists - from the lyrical storytelling of Johnny Cash to the raw energy of Linkin Park. There’s something satisfying about building a data pipeline that analyzes the music that’s been the soundtrack to different phases of my life. It turns what could be just another technical exercise into something personally meaningful.
Defining Our Assets
First things first - let’s import everything we’ll need to create this module:
#./assets.py
import json
import os
from datetime import UTC, datetime
from pathlib import Path
from typing import Literal, Optional
from dagster import AssetExecutionContext, AssetKey, MaterializeResult, MetadataValue, asset
from dagster_duckdb import DuckDBResource
from .partitions import ARTISTS
from .resources import SpotifyAPINow, before diving into the assets, let’s create a utility class that helps manage our Data Lake paths:
#./assets.py
class Layer:
"""Access patterns for Data Lake layers."""
@staticmethod
def _exists(path: str) -> str:
"""Internal method that ensures directory exists for the given path."""
Path(path).parent.mkdir(parents=True, exist_ok=True)
return path
@staticmethod
def bronze(asset: str, artist: Optional[str] = None, mode: Literal["read", "write"] = "read") -> str:
"""Path for `bronze` layer asset."""
if mode == "read":
return f"data/bronze/{artist}/{asset}.json" if artist else f"data/bronze/*/{asset}.json"
return Layer._exists(path=f"data/bronze/{artist}/{asset}.json")
@staticmethod
def silver(asset: str, mode: Literal["read", "write"] = "read") -> str:
"""Path for `silver` layer asset."""
path: str = f"data/silver/{asset}"
return f"{path}/*/*.parquet" if mode == "read" else Layer._exists(path=path)
@staticmethod
def gold(asset: str, mode: Literal["read", "write"] = "read") -> str:
"""Path for `gold` layer asset."""
path: str = f"data/gold/{asset}"
return f"{path}/*.parquet" if mode == "read" else Layer._exists(path=path)The Layer class addresses path management in our Data Lake architecture. It creates a consistent interface for accessing data at different stages of processing, handles directory creation automatically, and maintains naming conventions across the pipeline. This simple utility prevents those frustrating troubleshooting sessions when files aren’t where you expect them to be.
This seemingly simple utility actually solves a substantial challenge in Data Engineering - maintaining consistency in how data is organized and accessed. By abstracting path management, we can focus on the transformations themselves rather than worrying about file locations and directory structures.
bronze
The bronze layer forms the foundation of our pipeline. Here, we focus on reliably extracting data from Spotify and preserving it in its original form. Let’s create our first bronze asset:
#./assets.py
@asset(
name="artist",
key_prefix="bronze",
group_name="spotify",
partitions_def=ARTISTS,
kinds={"bronze", "python", "json"},
description="Artist profile data from Spotify API in raw json format.",
)
def bronze__artist(context: AssetExecutionContext, spotify: SpotifyAPI) -> MaterializeResult:
artist: str = context.partition_key
path: str = Layer.bronze(asset="artist", artist=artist, mode="write")
data: dict = spotify.get_artist(artist=artist)
with open(file=path, mode="w") as file:
json.dump(data, file, indent=2)
return MaterializeResult(
metadata={
"Artist": MetadataValue.text(artist),
"File": MetadataValue.path(path),
"File Size (KB)": MetadataValue.float(os.path.getsize(path) / 1024),
"Timestamp": MetadataValue.timestamp(datetime.now(UTC)),
}
)This bronze asset has a clear responsibility - extract artist data from the Spotify API and store it as raw .json. The simplicity is intentional; we want reliable data capture with minimal processing. The code focuses purely on extraction - there’s no transformation logic mixed in, keeping concerns properly separated.
There are several design choices worth highlighting here. We’re using partitioning to process one artist at a time, which gives us flexibility in how we schedule and execute the pipeline. The asset returns detailed metadata about what it produced, making monitoring easier through Dagster’s UI. We’re also using a consistent path structure via our Layer utility.
Using the same pattern, we create similar bronze assets for albums and top tracks:
#./assets.py
@asset(
name="artist_albums",
key_prefix="bronze",
group_name="spotify",
partitions_def=ARTISTS,
kinds={"bronze", "python", "json"},
description="Artist album catalog from Spotify API in raw json format."
)
def bronze__artist_albums(context: AssetExecutionContext, spotify: SpotifyAPI) -> MaterializeResult:
artist: str = context.partition_key
path: str = Layer.bronze(asset="artist_albums", artist=artist, mode="write")
data: dict = spotify.get_artist_albums(artist=artist)
with open(file=path, mode="w") as file:
json.dump(data, file, indent=2)
return MaterializeResult(
metadata={
"Artist": MetadataValue.text(artist),
"File": MetadataValue.path(path),
"File Size (KB)": MetadataValue.float(os.path.getsize(path) / 1024),
"Timestamp": MetadataValue.timestamp(datetime.now(UTC)),
}
)
@asset(
name="artist_top_tracks",
key_prefix="bronze",
group_name="spotify",
partitions_def=ARTISTS,
kinds={"bronze", "python", "json"},
description="Artist top tracks from Spotify API in raw json format."
)
def bronze__artist_top_tracks(context: AssetExecutionContext, spotify: SpotifyAPI) -> MaterializeResult:
artist: str = context.partition_key
path: str = Layer.bronze(asset="artist_top_tracks", artist=artist, mode="write")
data: dict = spotify.get_artist_top_tracks(artist=artist)
with open(file=path, mode="w") as file:
json.dump(data, file, indent=2)
return MaterializeResult(
metadata={
"Artist": MetadataValue.text(artist),
"File": MetadataValue.path(path),
"File Size (KB)": MetadataValue.float(os.path.getsize(path) / 1024),
"Timestamp": MetadataValue.timestamp(datetime.now(UTC)),
}
)
These assets follow the same design principles, just targeting different API endpoints. Each maintains its independence, allowing us to refresh album data without needing to re-fetch artist profiles or track information.
silver
With our raw data securely captured, we can transform it into more analytics-friendly formats. Let’s create our first silver asset:
#./assets.py
@asset(
name="artist",
key_prefix="silver",
group_name="spotify",
partitions_def=ARTISTS,
kinds={"silver", "duckdb", "parquet"},
deps=[AssetKey(["bronze", "artist"])],
description="Artist profile data from Spotify API in structured parquet format.",
)
def silver__artist(context: AssetExecutionContext, duckdb: DuckDBResource) -> MaterializeResult:
artist: str = context.partition_key
path: str = Layer.silver(asset="artist", mode="write")
with duckdb.get_connection() as connection:
connection.execute(
query=f"""
COPY (
SELECT
name AS artist,
id,
genres,
popularity,
followers.total AS total_followers
FROM read_json_auto('{Layer.bronze(asset="artist", artist=artist, mode="read")}')
) TO '{path}'
(FORMAT parquet, PARTITION_BY artist, OVERWRITE_OR_IGNORE);
"""
)
return MaterializeResult(
metadata={
"Artist": MetadataValue.text(artist),
"File": MetadataValue.path(path),
"File Size (KB)": MetadataValue.float(os.path.getsize(path) / 1024),
"Timestamp": MetadataValue.timestamp(datetime.now(UTC)),
}
)This asset transforms raw artist .json into structured .parquet format using DuckDB. The SQL query performs several key operations. It selects only the fields we need, such as name, id, and genres, avoiding the overhead of carrying unused data forward. It flattens nested structures like the followers object, making the data easier to query and analyze. Finally, the output is partitioned by artist, maintaining our organization pattern throughout the pipeline.
For the silver and gold transformations, DuckDB proves to be an excellent choice. It handles .json parsing remarkably well with functions like read_json_auto(), which automatically infers the schema from nested structures. The SQL syntax is both familiar and powerful, supporting advanced operations like UNNEST for those nested arrays of artists. Perhaps most importantly, DuckDB’s seamless integration with .parquet files creates a natural fit for our Medallion Architecture, efficiently transforming our .json data into columnar storage optimized for the analytical queries.
Following the same pattern, we create silver assets for the albums and top tracks:
#./assets.py
@asset(
name="artist_albums",
key_prefix="silver",
group_name="spotify",
partitions_def=ARTISTS,
kinds={"silver", "duckdb", "parquet"},
deps=[AssetKey(["bronze", "artist_albums"])],
description="Artist album catalog from Spotify API in structured parquet format.",
)
def silver__artist_albums(context: AssetExecutionContext, duckdb: DuckDBResource) -> MaterializeResult:
artist: str = context.partition_key
path: str = Layer.silver(asset="artist_albums", mode="write")
with duckdb.get_connection() as connection:
connection.execute(
query=f"""
COPY (
SELECT
artists.unnest.name AS artist,
artists.unnest.id AS artist_id,
albums.id,
albums.name,
albums.release_date,
albums.total_tracks,
albums.album_type
FROM read_json_auto('{Layer.bronze(asset="artist_albums", mode="read")}') AS albums,
UNNEST(albums.artists) AS artists
) TO '{path}'
(FORMAT parquet, PARTITION_BY artist, OVERWRITE_OR_IGNORE);
"""
)
return MaterializeResult(
metadata={
"Artist": MetadataValue.text(artist),
"File": MetadataValue.path(path),
"File Size (KB)": MetadataValue.float(os.path.getsize(path) / 1024),
"Timestamp": MetadataValue.timestamp(datetime.now(UTC)),
}
)
@asset(
name="artist_top_tracks",
key_prefix="silver",
group_name="spotify",
partitions_def=ARTISTS,
kinds={"silver", "duckdb", "parquet"},
deps=[AssetKey(["bronze", "artist_top_tracks"])],
description="Artist top tracks from Spotify API in structured parquet format.",
)
def silver__artist_top_tracks(context: AssetExecutionContext, duckdb: DuckDBResource) -> MaterializeResult:
artist: str = context.partition_key
path: str = Layer.silver(asset="artist_top_tracks", mode="write")
with duckdb.get_connection() as connection:
connection.execute(
query=f"""
COPY (
SELECT
artists.unnest.name AS artist,
artists.unnest.id AS artist_id,
tracks.album.id AS album_id,
tracks.id,
tracks.name,
tracks.duration_ms,
tracks.explicit,
tracks.popularity,
tracks.is_local,
tracks.is_playable,
tracks.track_number
FROM
read_json_auto('{Layer.bronze(asset="artist_top_tracks", mode="read")}') AS tracks,
UNNEST(tracks.artists) AS artists
) TO '{path}'
(FORMAT parquet, PARTITION_BY artist, OVERWRITE_OR_IGNORE);
"""
)
return MaterializeResult(
metadata={
"Artist": MetadataValue.text(artist),
"File": MetadataValue.path(path),
"File Size (KB)": MetadataValue.float(os.path.getsize(path) / 1024),
"Timestamp": MetadataValue.timestamp(datetime.now(UTC)),
}
)
These assets apply similar transformations to their respective datasets. The album transformation extracts information about album type and release dates, while the tracks transformation captures popularity metrics and track details. Both use SQL’s UNNEST operator to handle the nested artist arrays in Spotify’s API responses.
gold
The gold layer represents the culmination of our pipeline - where transformed data becomes meaningful insights:
#./assets.py
@asset(
name="artist_insights",
key_prefix="gold",
group_name="spotify",
kinds={"gold", "duckdb", "parquet"},
deps=[
AssetKey(["silver", "artist"]),
AssetKey(["silver", "artist_top_tracks"]),
AssetKey(["silver", "artist_albums"]),
],
description="Consolidated artist insights combining profile, album, and track metrics.",
)
def gold__artist_insights(context: AssetExecutionContext, duckdb: DuckDBResource) -> MaterializeResult:
path: str = Layer.gold(asset="artist_insights", mode="write")
with duckdb.get_connection() as connection:
connection.execute(
query=f"""
COPY (
-- Base artist information
WITH artist_base AS (
SELECT
artist,
id AS artist_id,
popularity AS artist_popularity,
total_followers
FROM '{Layer.silver(asset="artist", mode="read")}'
),
-- Album metrics aggregated by artist
album_metrics AS (
SELECT
artist_id,
AVG(total_tracks) AS avg_tracks_per_album,
MIN(release_date) AS first_album_date,
MAX(release_date) AS latest_album_date
FROM '{Layer.silver(asset="artist_albums", mode="read")}'
GROUP BY artist_id
),
-- Track metrics aggregated by artist
track_metrics AS (
SELECT
artist_id,
AVG(popularity) AS avg_track_popularity,
AVG(duration_ms)/1000 AS avg_track_duration_seconds,
SUM(CASE WHEN explicit THEN 1 ELSE 0 END)::FLOAT / COUNT(id) * 100 AS explicit_content_percentage
FROM '{Layer.silver(asset="artist_top_tracks", mode="read")}'
GROUP BY artist_id
),
-- Top track for each artist
top_tracks AS (
SELECT DISTINCT ON (artist_id)
artist_id,
id AS track_id,
name AS track_name,
popularity AS track_popularity,
album_id
FROM '{Layer.silver(asset="artist_top_tracks", mode="read")}'
ORDER BY artist_id, popularity DESC
),
-- Album info for lookup
album_lookup AS (
SELECT
id AS album_id,
name AS album_name
FROM '{Layer.silver(asset="artist_albums", mode="read")}'
)
-- Final insights table
SELECT
artist_info.artist,
artist_info.artist_id,
artist_info.artist_popularity,
artist_info.total_followers,
-- Album metrics
artist_albums.avg_tracks_per_album,
artist_albums.first_album_date,
artist_albums.latest_album_date,
-- Track metrics
artist_tracks.avg_track_popularity,
artist_tracks.avg_track_duration_seconds,
artist_tracks.explicit_content_percentage,
-- Top track info
popular_track.track_name AS top_track_name,
popular_track.track_popularity AS top_track_popularity,
track_album.album_name AS top_track_album
FROM artist_base AS artist_info
LEFT JOIN album_metrics AS artist_albums
ON artist_info.artist_id = artist_albums.artist_id
LEFT JOIN track_metrics AS artist_tracks
ON artist_info.artist_id = artist_tracks.artist_id
LEFT JOIN top_tracks AS popular_track
ON artist_info.artist_id = popular_track.artist_id
LEFT JOIN album_lookup AS track_album
ON popular_track.album_id = track_album.album_id
) TO '{path}'
(FORMAT parquet, OVERWRITE);
"""
)
return MaterializeResult(
metadata={
"File": MetadataValue.path(path),
"File Size (KB)": MetadataValue.float(os.path.getsize(path) / 1024),
"Timestamp": MetadataValue.timestamp(datetime.now(UTC)),
}
)Our gold asset combines data from all three silver datasets into a consolidated view of artist insights. Unlike the bronze and silver assets that process one artist at a time, this gold asset aggregates across all artists to create a comprehensive dataset.
The SQL query is more complex for good reason - it’s creating something genuinely valuable. It creates CTEs for each aspect of artist data, including base information, album metrics, and track metrics. The query calculates meaningful aggregations such as average tracks per album and average track popularity across each artist’s catalog. It identifies each artist’s most popular track, providing a quick reference point for their standout content. Finally, it joins all this information together into a single, analysis-ready dataset that provides a complete picture of each artist.
This thoughtfully designed asset creates a dataset that answers important questions: Which artist has the highest track popularity? How does track duration correlate with popularity? What percentage of an artist’s content is explicit? The gold layer is where data becomes insight - where we transform technically accurate information into business-relevant knowledge. This is the layer that typically gets presented to stakeholders, and the one that ultimately justifies all the careful engineering that came before it.
Setting Up the Definitions
To finish our project, we now only need to put it all together to enable Dagster to load these components. This can be done in a dunder init file, but to make it clearer, let’s create a dedicated file to centralize this concern:
# ./definitions.py
import os
from dagster import Definitions, load_assets_from_modules
from dagster_duckdb import DuckDBResource
from . import assets, resources
SPOTIFY_API_CLIENT_ID: str = os.getenv("SPOTIFY_API_CLIENT_ID")
SPOTIFY_API_CLIENT_SECRET: str = os.getenv("SPOTIFY_API_CLIENT_SECRET")
defs = Definitions(
assets=load_assets_from_modules([assets]),
resources={
"spotify": resources.SpotifyAPI(
client_id=SPOTIFY_API_CLIENT_ID,
client_secret=SPOTIFY_API_CLIENT_SECRET,
),
"duckdb": DuckDBResource(
database=":memory:",
read_only=False,
),
},
)When Dagster initializes, it will load everything included in the Definitions object. If we had created jobs, schedules, or sensors, they would also be included here. This acts as a central entry point for the project deployment - for a component to be deployed and visible in the Dagster UI, it must be set in a Definitions object.
For this demonstration, we’re using DuckDB’s in-memory mode, which is perfect for our needs. Since we’re only using DuckDB as a processing engine to transform data between our layers and materializing all results as .parquet files, we don’t need to persist the database itself.
Pressing Play
With our code and configuration in place, let’s see the pipeline in action. Once your Python virtual environment is activated, starting a local Dagster development instance requires a simple command:
dagster devThis will initialize the entire project and open the local UI:
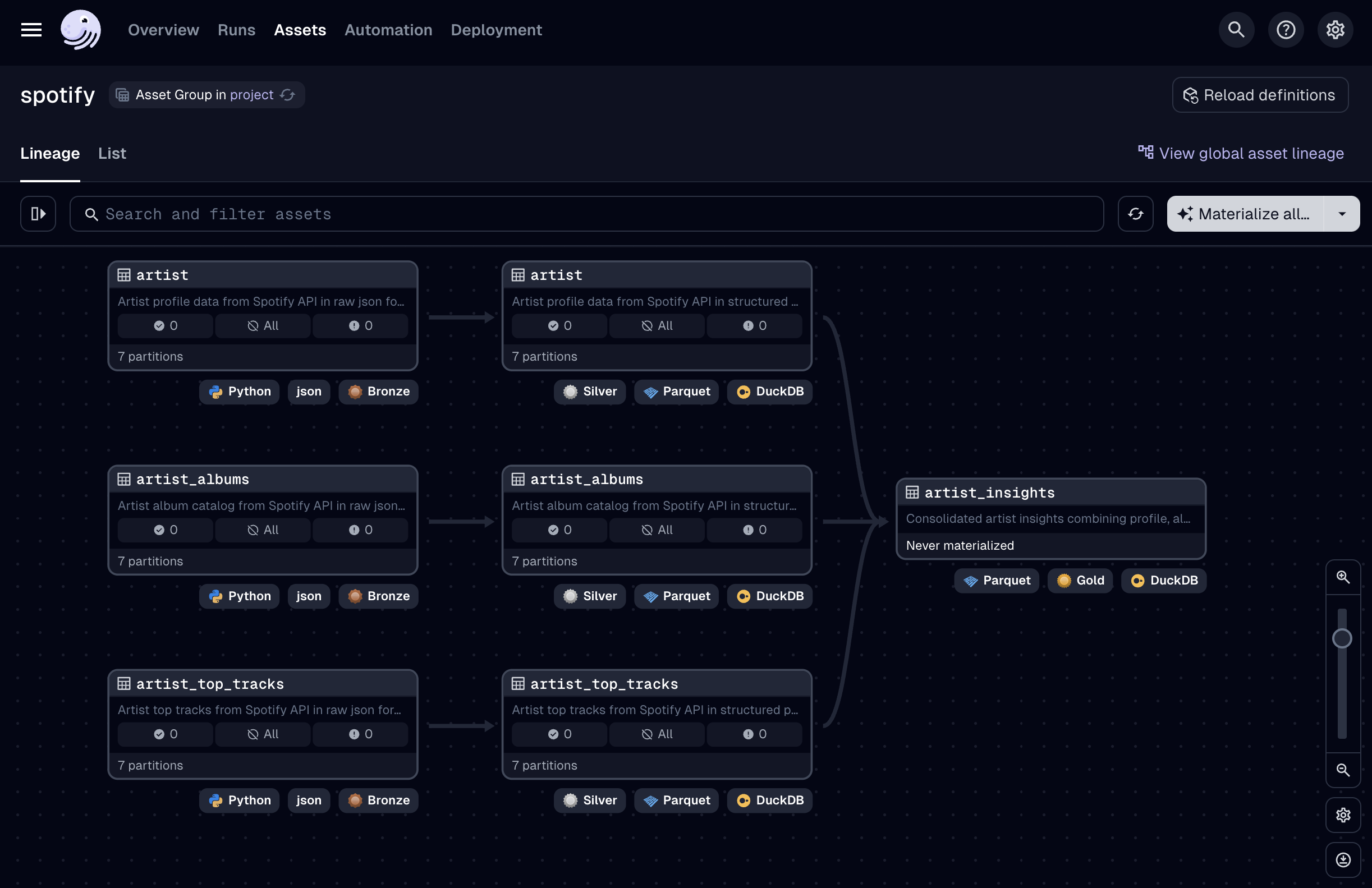
I won’t make a full tour of the UI in this project, but instead focus on the assets themselves. As you can see, our code is rendered in this stylish dark-themed lineage graph (you can change it to a light theme too if you prefer), where you can clearly see the asset dependencies flowing from left to right and their current status. Since we haven’t materialized any assets yet - which means executing the code to generate the actual data outputs and store them in physical storage, all asset partitions are marked as missing and our gold asset shows _Never materialized.
A nice touch is the tags at the bottom of each asset (like bronze, python, json) that visually indicate the purpose and technology behind each component without requiring us to examine the code. There’s an extensive list of kind tags available in Dagster, and the system is open to contributions if you need custom ones.
Let’s try materializing a single partition of one asset to see how it works. Right-click on any bronze asset and select Materialize. The materialization context will show you the list of available partitions - you can choose one or more partitions to start the materialization or select them all (which would lead to a backfill run). Let’s choose a single one and click Launch run. You’ll see the asset status changing in real-time, and when the materialization finishes, we can examine the asset details in the Asset Catalog:
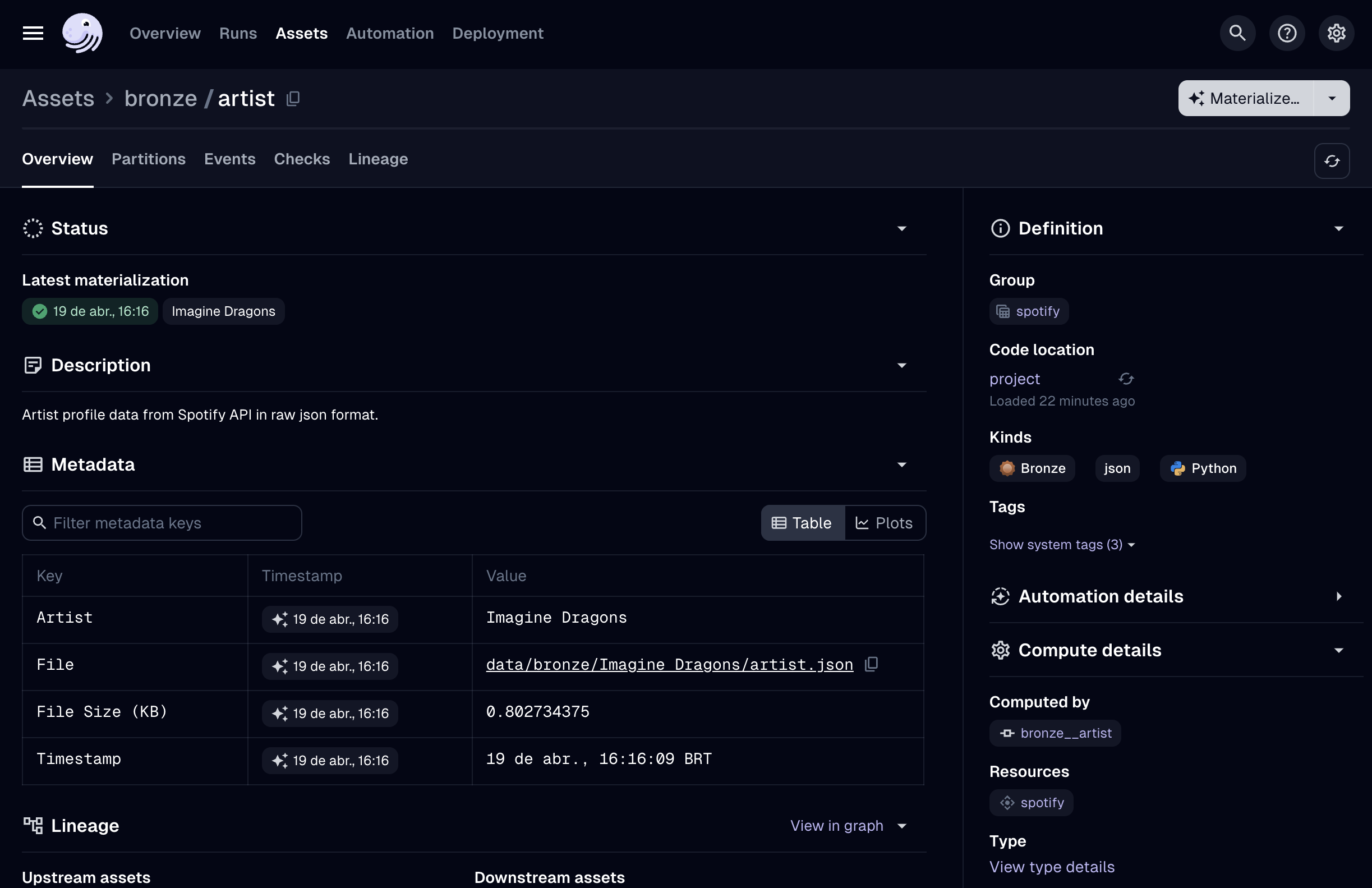
Notice how the metadata we configured in our code is displayed here in the Overview tab. If a metadata item is numeric, Dagster can also generate plots automatically - particularly useful for tracking the volume of rows if the asset represents a table. This metadata can even be accessed programmatically by other Dagster components.
There are several other tabs worth exploring: the Partitions tab shows the status of each partition with timestamps and run IDs; the Events tab displays all actions related to the asset, providing a complete history of materializations; the Checks tab shows quality tests for your assets (a powerful feature we’re not using in this demo); and the Lineage tab visualizes the upstream and downstream dependencies of the selected asset.
Now let’s return to the main graph and click the white Materialize All button in the top right. This will again open the partition selection context, where we can select all partitions. When you launch this run, you’ll see that Dagster beautifully handles the execution, respecting the dependencies between assets and partitions. You’ll also observe files being created in our Medallion folder structure as each asset completes. When finished, all assets and partitions should be materialized, with the graph showing green status indicators:
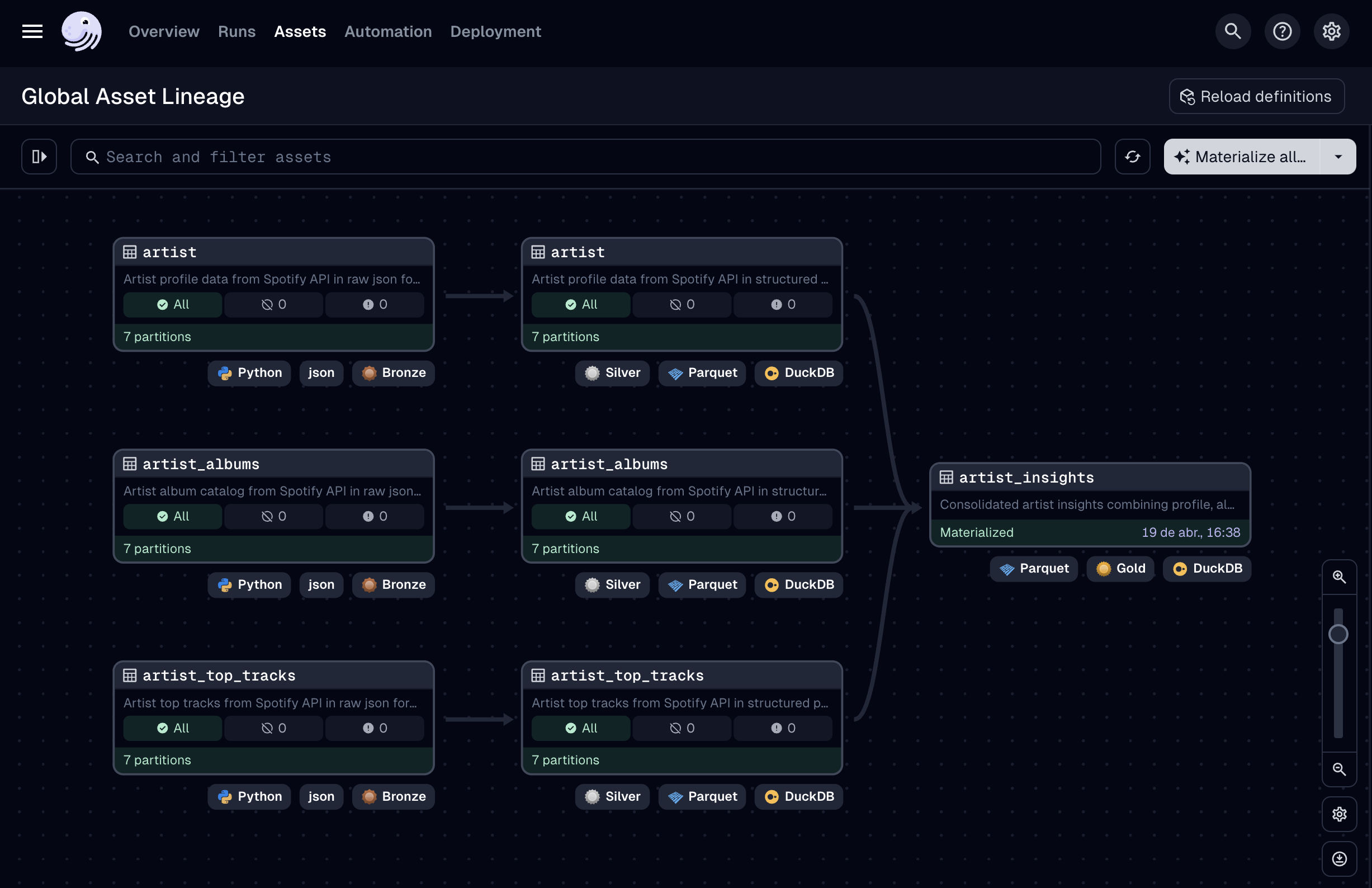
Now it’s time to see if we got the expected results.
Analyzing Our Results
I’ve tested this workflow step-by-step multiple times, but let’s cut to the chase and check the final output. To do this, we just need to query the artist_insights .parquet file using DuckDB:
SELECT * FROM read_parquet("data/gold/artist_insights")And we get something like:
┌───────────────────────┬────────────────────────┬───────────────────┬─────────────────┬──────────────────────┬──────────────────┬───────────────────┬──────────────────────┬────────────────────────────┬─────────────────────────────┬────────────────┬──────────────────────┬───────────────────────────────────┐
│ artist │ artist_id │ artist_popularity │ total_followers │ avg_tracks_per_album │ first_album_date │ latest_album_date │ avg_track_popularity │ avg_track_duration_seconds │ explicit_content_percentage │ top_track_name │ top_track_popularity │ top_track_album │
│ varchar │ varchar │ int64 │ int64 │ double │ varchar │ varchar │ double │ double │ float │ varchar │ int64 │ varchar │
├───────────────────────┼────────────────────────┼───────────────────┼─────────────────┼──────────────────────┼──────────────────┼───────────────────┼──────────────────────┼────────────────────────────┼─────────────────────────────┼────────────────┼──────────────────────┼───────────────────────────────────┤
│ Charlie Brown Jr. │ 1on7ZQ2pvgeQF4vmIA09x5 │ 77 │ 8297699 │ 14.681818181818182 │ 1997-01-01 │ 2024-11-29 │ 71.8 │ 209.86010000000002 │ 0.0 │ Zóio De Lula │ 74 │ Preço Curto, Prazo Longo │
│ Eminem │ 7dGJo4pcD2V6oG8kP0tJRR │ 92 │ 99748616 │ 10.3 │ 1996-11-12 │ 2024-12-12 │ 84.7 │ 290.09229999999997 │ 100.0 │ Without Me │ 89 │ The Eminem Show │
│ Imagine Dragons │ 53XhwfbYqKCa1cC15pYq2q │ 88 │ 57006678 │ 5.58 │ 2012-09-04 │ 2025-02-21 │ 83.4 │ 193.8215 │ 0.0 │ Believer │ 88 │ Evolve │
│ Johnny Cash │ 6kACVPfCOnqzgfEF5ryl0x │ 76 │ 6711049 │ 19.88 │ 1979-05-01 │ 2025-02-11 │ 70.4 │ 181.71089999999998 │ 0.0 │ Hurt │ 76 │ American IV: The Man Comes Around │
│ Linkin Park │ 6XyY86QOPPrYVGvF9ch6wz │ 90 │ 29644064 │ 11.74 │ 2000-10-24 │ 2025-03-27 │ 85.1 │ 189.262 │ 10.0 │ Numb │ 90 │ NULL │
│ Red Hot Chili Peppers │ 0L8ExT028jH3ddEcZwqJJ5 │ 85 │ 22377753 │ 10.28888888888889 │ 1984-08-10 │ 2022-11-25 │ 82.2 │ 270.201 │ 0.0 │ Can't Stop │ 88 │ By the Way (Deluxe Edition) │
│ Twenty One Pilots │ 3YQKmKGau1PzlVlkL1iodx │ 85 │ 25286775 │ 4.67741935483871 │ 2009-12-29 │ 2025-04-09 │ 79.6 │ 212.5751 │ 0.0 │ Stressed Out │ 87 │ Blurryface │
└───────────────────────┴────────────────────────┴───────────────────┴─────────────────┴──────────────────────┴──────────────────┴───────────────────┴──────────────────────┴────────────────────────────┴─────────────────────────────┴────────────────┴──────────────────────┴───────────────────────────────────┘
- The artist with the highest number of followers is Eminem (nearly 100 million!) and, to no one’s surprise, 100% of his tracks we extracted have explicit content.
- Imagine Dragons has the second-highest follower count at 57 million, but interestingly, Linkin Park is marked as more popular - according to Spotify’s API docs, an artist’s popularity is calculated from the popularity of all their tracks rather than just follower count.
- I think few would disagree that Johnny Cash’s version of Hurt is superior to the original by Nine Inch Nails, and our data shows it’s indeed his most popular track.
- I’m also delighted to see Imagine Dragons’ Believer as their top track; it’s actually my favorite song and was even part of my wedding ceremony.
That’s it! We’ve built an entire data pipeline from scratch using only free and open-source tools. This pipeline pattern can adapt to much larger workloads - the architecture remains valid whether processing data for a handful of artists or scaling to thousands. Dagster’s asset-oriented approach grows with your needs while maintaining the same fundamental principles.
If you want to experiment further, you might try adding more artists, implementing scheduled refreshes using Dagster’s scheduling capabilities, or connecting a visualization tool to create dashboards from the insights data.
Of course, our design here was simplified to match this standalone project’s objective: to explore Dagster’s asset-oriented approach and how it transforms well-written code into reliable Data Engineering components. The Spotify API has extraction volume limitations we haven’t covered in this project; you may also encounter errors related to unhandled DuckDB multi-write operations in more complex implementations.
It was a fun project to build, and I hope you enjoyed exploring Dagster’s capabilities through this musical lens!
Encore: Applying the Factory Pattern
I’m a big fan of keeping code DRY, and Dagster opens up excellent opportunities for creating elegant abstractions. Let’s apply a factory pattern to transform our asset creation into something more production-ready and maintainable. By the way, if you’re interested in this topic, Dagster’s Factory Patterns in Python article is essential reading.
Let’s start by creating a .yaml configuration file that defines our assets:
# encore/assets.yaml
bronze:
- name: artist
description: Artist profile data from Spotify API in raw json format.
- name: artist_albums
description: Artist album catalog from Spotify API in raw json format.
- name: artist_top_tracks
description: Artist top tracks from Spotify API in raw json format.Now, let’s strengthen our abstraction with some Pydantic models to ensure type safety and validation:
# encore/assets.py
class Metadata(BaseModel):
"""Pydantic model for asset metadata."""
artist: str = Field(..., description="Artist name from partition key")
file: Path = Field(..., description="Path to the asset file")
def to_dagster_metadata(self) -> dict[str, MetadataValue]:
"""Convert this model to Dagster metadata."""
return {
"Artist": MetadataValue.text(self.artist),
"File": MetadataValue.path(str(self.file)),
"File Size (KB)": MetadataValue.float(self.file.stat().st_size / 1024),
"Timestamp": MetadataValue.timestamp(datetime.now(UTC)),
}
class BronzeAssetSpec(BaseModel):
"""Pydantic model for bronze layer asset specification."""
name: str
description: str
@computed_field
def api_method(self) -> str:
"""Derive API method name from asset name."""
return f"get_{self.name}"Next comes our AssetFactory component. For simplicity, I’ll only create factories for bronze assets, but the pattern can easily extend to silver and gold layers as well. The core idea is simple: create a function that returns asset-decorated functions, which themselves generate asset definitions. This approach allows us to parametrize any configuration needed for asset creation:
# encore/assets.py
class AssetFactory:
"""Factory for creating Spotify data assets."""
@staticmethod
def bronze(spec: BronzeAssetSpec) -> AssetsDefinition:
"""Create a bronze layer asset from a specification."""
@asset(
name=spec.name,
key_prefix="bronze",
group_name="spotify",
partitions_def=ARTISTS,
kinds={"bronze", "python", "json"},
description=spec.description,
)
def _(context: AssetExecutionContext, spotify: SpotifyAPI) -> MaterializeResult:
artist: str = context.partition_key
path: str = Layer.bronze(asset=spec.name, artist=artist, mode="write")
# Dynamically call the Spotify resource API method
api = getattr(spotify, spec.api_method)
data = api(artist=artist)
# Write the data
with open(file=path, mode="w") as file:
json.dump(data, file, indent=2)
metadata = Metadata(artist=artist, file=path)
return MaterializeResult(metadata=metadata.to_dagster_metadata())
return _Finally, we need an AssetLoader component to inject the .yaml configuration into our factory. This component reads our configuration file, transforms it into validated Pydantic models, and feeds those to our factory:
# encore/assets.py
class AssetLoader:
"""Loads and creates assets from configuration."""
@staticmethod
@cache
def load_config(path: str) -> dict:
"""Load and cache asset configuration."""
return yaml.safe_load(Path(path).read_text())
@classmethod
def bronze(cls, path: str = "project/encore/assets.yaml") -> list[AssetsDefinition]:
"""Create all bronze assets from the configuration file."""
config: dict = cls.load_config(path)
specs: list[BronzeAssetSpec] = [
BronzeAssetSpec.model_validate(item) for item in config["bronze"]
]
# Create dictionary of assets using dictionary comprehension
return [AssetFactory.bronze(spec) for spec in specs]To load these assets, we simply need one line of code:
# encore/assets.py
assets: list[AssetsDefinition] = AssetLoader.bronze()When we start our local Dagster instance, the bronze assets will appear in the UI:
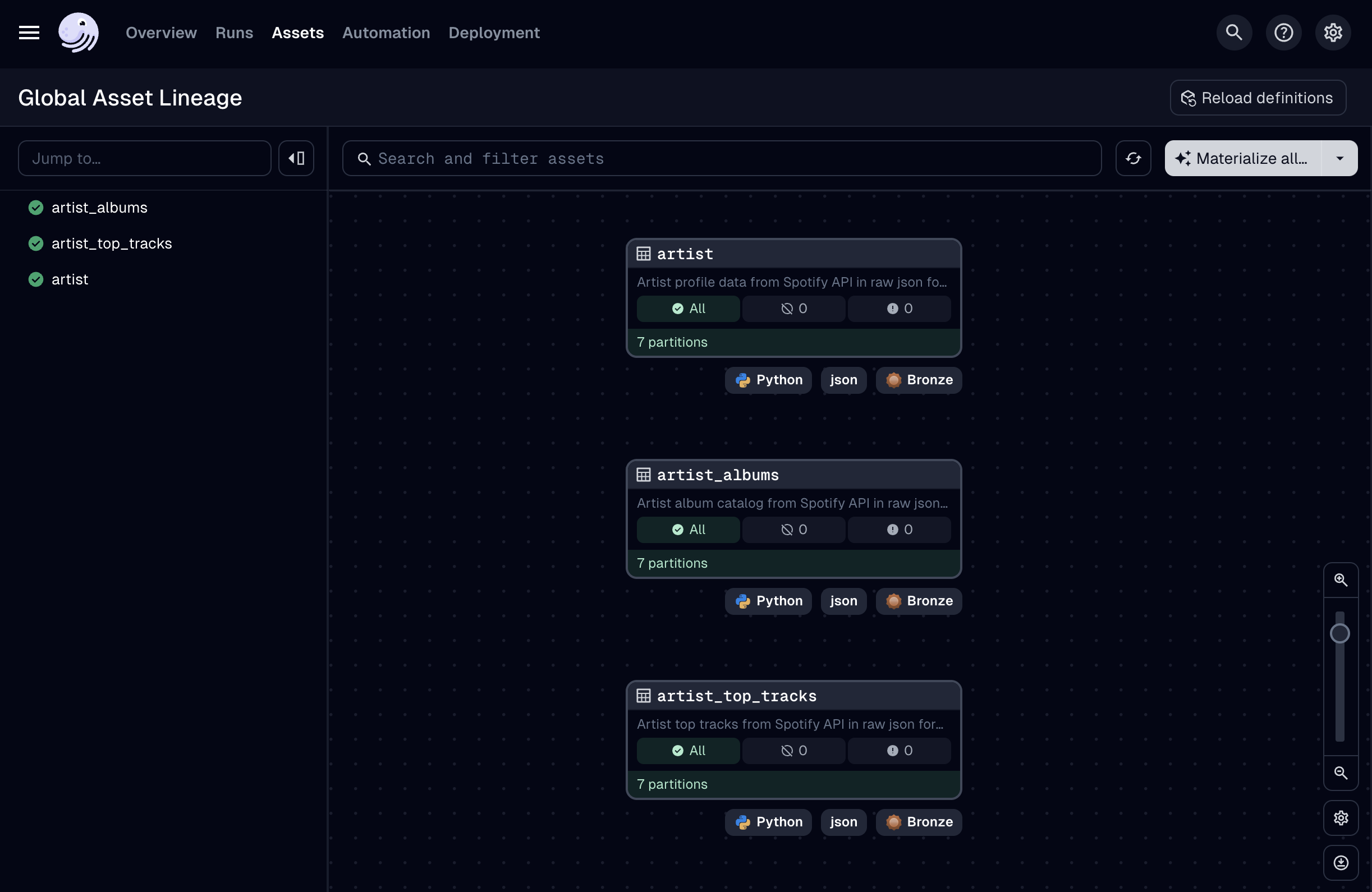
The beauty of this approach is that adding a new asset requires no code changes - just a simple addition to the .yaml file. This separation of configuration from implementation embodies best practices in modern Data Engineering, making your codebase more resilient and adaptable.
Is it worth the extra abstraction? Well, ask yourself this: would you rather write the same code pattern 10 times, or write one smart pattern that works for all 10 cases? If you’re handling more than 3-4 similar assets, the factory approach isn’t just elegant - it’s practical time-saving engineering. Remember, the goal isn’t abstraction for abstraction’s sake. It’s about spending your mental energy on solving new problems rather than typing the same definitions over and over.